Week 5: Exploratory Data Analysis
PUBPOL 750 Data Analysis for Public Policy I
Justin Savoie
MPP-DS McMaster
2022-06-10
Summary to date
Visualization
Transformation
Tidy data
Exploratory Data Analysis (EDA)
"There are no routine statistical questions, only questionable statistical routines." - Sir David Cox
"Far better an approximate answer to the right question, which is often vague, than an exact answer to the wrong question, which can always be made precise." - John Tukey
Your goal during EDA is to develop an understanding of your data.
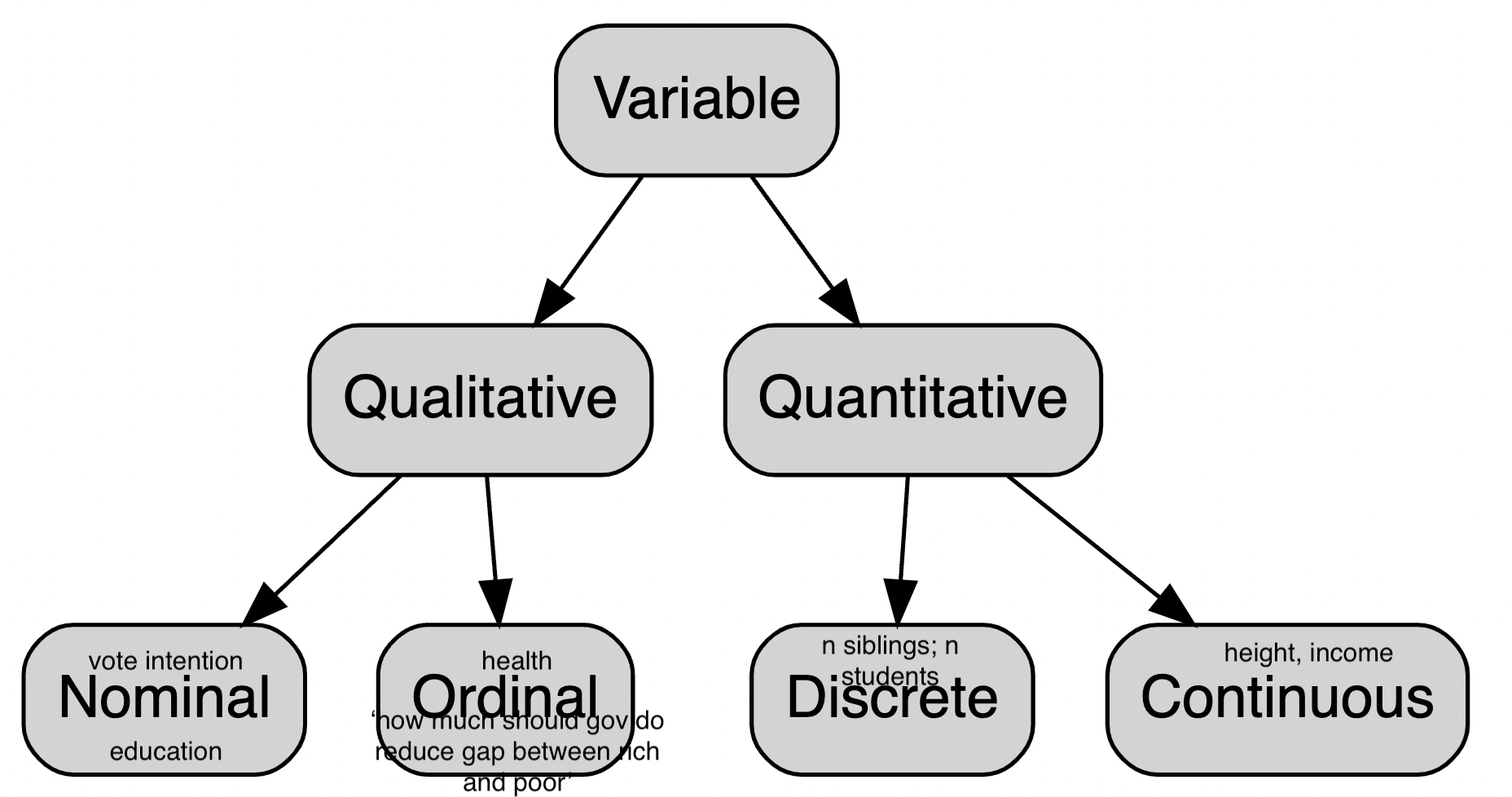
Some terms
A variable is a quantity, quality, or property that you can measure. (e.g. satisfaction with policy)
A value is the state of a variable when you measure it. The value of a variable may change from measurement to measurement. (e.g. Very dissastified, Somewhat dissatisfied, etc.)
An observation is a set of measurements made under similar conditions (you usually make all of the measurements in an observation at the same time and on the same object). An observation will contain several values, each associated with a different variable. (e.g. Mrs De la Hoya's answers to all questions in the survey)
Tabular data is a set of values, each associated with a variable and an observation. (e.g. your data that fits in a spreadsheed, where rows are individuals and columns variables)
Transformations
Convert ordinal to numeric. e.g. (Q1) How much should the government do to reduce the gap between the rich and the poor? - (1) Much less (2) Somewhat less (3) About the same as now (4) Somewhat more (5) Much more (6) Don't know. (Q1) is called a Likert-type question. The choices are a Likert scale. Likert (3-choices) (5-choices) or (7-choices) are common in social sciences. They are often converted to numeric. But then, you need to decide what to do with "(6) Don't know." ... Can drop it. Can put it as (3-middle-category).
Convert income numeric to brackets (e.g. <30k, 30-60k ...)
Age to age groups
If you have vote intention maybe you want to convert intention to e.g. "Liberal vs the rest" Or maybe "CPC + PPC" vs the rest.
Convert a binary category to 1 and 0. e.g. Liberal = 1, the rest = 0.
Convert income brackets to numeric (e.g. using the median of the bracket). This is seldom done.
Check the codebook!!!
- female / male / other coded as 1,2,99
- female / male / other coded as 1,2,3
- female / male / other coded as 1,2,3,-99
female / male / other coded as 1,2,3,60
a scale from 0-10 coded as 1 to 11 !!!
Variable types in R
R has six data types (character, numeric, integer, logical, complex, raw). But this is not very important.
For more info: https://swcarpentry.github.io/r-novice-inflammation/13-supp-data-structures/
R has data structures (vectors, list, matrix, data frame, factor). For now we can ignore lists and matrices.
A tidy data set is a data frame. It's also called a tibble. A tibble is the tidyverse version of the data frame.
A data frame has columns that are variables. Those variables can be numbers, character strings or factors. If you extract those variables from the data frame they become vectors. So the columns of the data frame are vectors.
Numbers and character strings that's straightforward. Factors are labels of text "over" numbers.
Data frames (and vectors/variables)
mtcars$cyl## [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4mtcars %>% pull(cyl)## [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4# get second columnmtcars[,2]## [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4# get second rowmtcars[2,]## mpg cyl disp hp drat wt qsec vs am gear carb## Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4Factors
mtcars$cyl## [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4factor(mtcars$cyl)## [1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4## Levels: 4 6 8as.character(mtcars$cyl)## [1] "6" "6" "4" "6" "8" "6" "8" "4" "4" "6" "6" "8" "8" "8" "8" "8" "8" "4" "4"## [20] "4" "4" "8" "8" "8" "8" "4" "4" "4" "8" "6" "8" "4"mtcars$cyl+1## [1] 7 7 5 7 9 7 9 5 5 7 7 9 9 9 9 9 9 5 5 5 5 9 9 9 9 5 5 5 9 7 9 5as.numeric(factor(mtcars$cyl))## [1] 2 2 1 2 3 2 3 1 1 2 2 3 3 3 3 3 3 1 1 1 1 3 3 3 3 1 1 1 3 2 3 1Factors
mtcars$cyl*2## [1] 12 12 8 12 16 12 16 8 8 12 12 16 16 16 16 16 16 8 8 8 8 16 16 16 16## [26] 8 8 8 16 12 16 8# as.character(mtcars$cyl)*2 (ERROR)factor(mtcars$cyl)*2## Warning in Ops.factor(factor(mtcars$cyl), 2): '*' not meaningful for factors## [1] NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA NA## [26] NA NA NA NA NA NA NAas.numeric(factor(mtcars$cyl))*2## [1] 4 4 2 4 6 4 6 2 2 4 4 6 6 6 6 6 6 2 2 2 2 6 6 6 6 2 2 2 6 4 6 2Factors
(df <- tibble(x=c(1,2,3),y=c("a","b","c")))## # A tibble: 3 × 2## x y ## <dbl> <chr>## 1 1 a ## 2 2 b ## 3 3 c(df$y_factor <- factor(df$y))## [1] a b c## Levels: a b cEDA on single variable OR univariate analysis
Is the variable a factor, a numeric, a character string ?
If the variable is continuous, you'll use a histogram.
If the variable is a numeric, but a count, you'll probably use a bar chart (like if it was a categorical variable).
If the variable is categorical, you'll use a bar chart.
If the variable is categorical, you will look at frequencies.
If the variable is continuous, you will look at min, max, median, mean, standard deviation, kurtosis, skewness.
Categorical variable
ggplot(data = diamonds) + geom_bar(mapping = aes(x = cut))
Categorical variable
diamonds %>% group_by(cut) %>% count()## # A tibble: 5 × 2## # Groups: cut [5]## cut n## <ord> <int>## 1 Fair 1610## 2 Good 4906## 3 Very Good 12082## 4 Premium 13791## 5 Ideal 21551Continuous variable
ggplot(data = diamonds) + geom_histogram(mapping = aes(x = carat), binwidth = 0.5)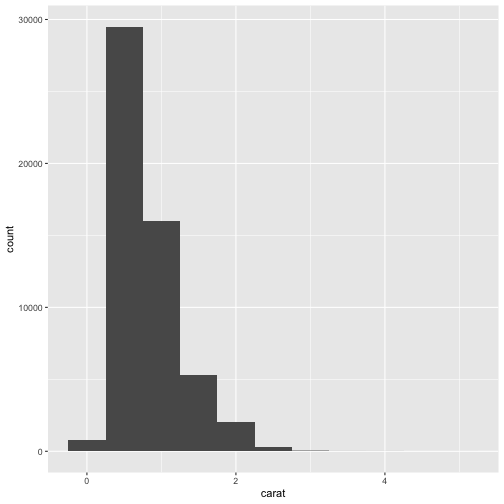
Continuous variable
diamonds %>% summarise(min=min(carat), max=max(carat), median=median(carat), mean=median(carat), sd=sd(carat), IQR=IQR(carat))## # A tibble: 1 × 6## min max median mean sd IQR## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>## 1 0.2 5.01 0.7 0.7 0.474 0.64Thinking about SD and IQR
Standard deviation and interquartile range are descriptions of your spread.
SD is the "amount of variation". Variance
Imagine in terms of soccer goals:
sd(c(0,1,2,0,0,1,0,2))## [1] 0.8864053sd(c(3,9,0,0,1,6))## [1] 3.656045- IQR gives the spread of the middle of the distribution. IQR is the third quartile minus the first quartile.
- quartile is a type of quantile which divides the number of data points into four parts.
- quantiles are cut points dividing the range of a probability distribution into continuous intervals with equal probabilities
IQR(c(0,1,2,0,0,1,0,2))## [1] 1.25IQR(c(3,9,0,0,1,6))## [1] 5quantile(c(3,9,0,0,1,6),c(0.25,0.75))## 25% 75% ## 0.25 5.25Other measures for continuous variable
- Skewness: if tail to the right > 0
- Skewness: if tail to the left < 0
- Kurtosis: if flat, platykurtic, < 0
- Kurtosis: if spiked, leptokurtic, > 0
library(e1071)plot(density(rnorm(1000,10,1)))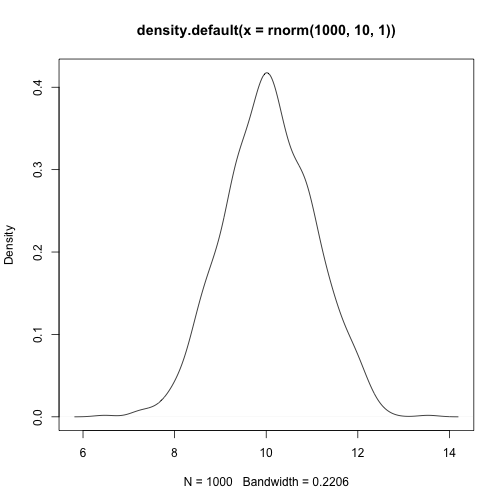
skewness(rnorm(1000,10,1))## [1] 0.1161583kurtosis(rnorm(1000,10,1))## [1] 0.1788358plot(density(rbeta(1000,1,10)))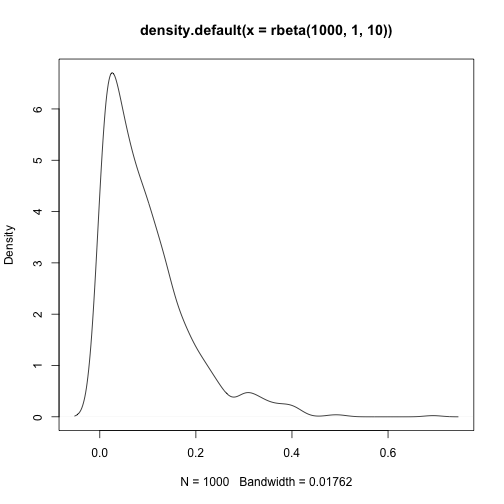
skewness(rbeta(1000,1,10))## [1] 1.571831kurtosis(rbeta(1000,1,10))## [1] 3.998467plot(density(rbeta(1000,10,1)))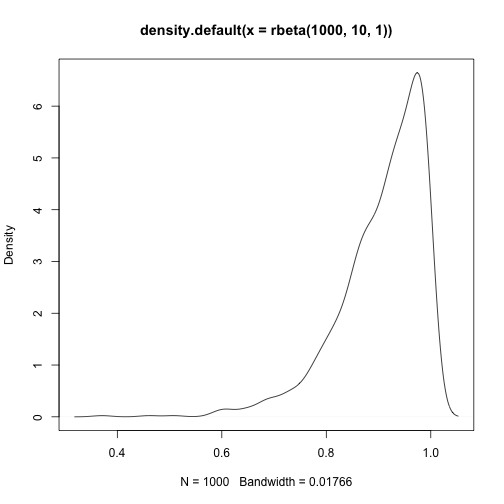
skewness(rbeta(1000,10,1))## [1] -1.540746kurtosis(rbeta(1000,10,1))## [1] 2.961721plot(density(rbeta(1000,2,2)))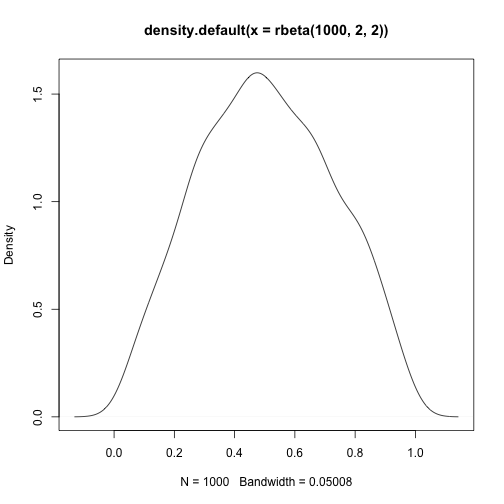
skewness(rbeta(1000,2,2))## [1] 0.02526159kurtosis(rbeta(1000,2,2))## [1] -0.8268801plot(density(rbeta(1000,2,4)))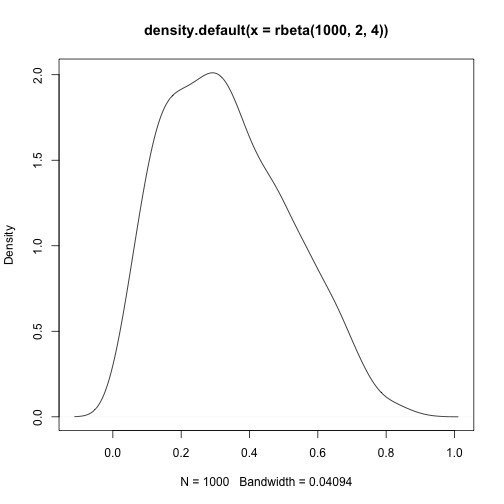
skewness(rbeta(1000,2,4))## [1] 0.5056963kurtosis(rbeta(1000,2,4))## [1] -0.4700893plot(density(rexp(10000)))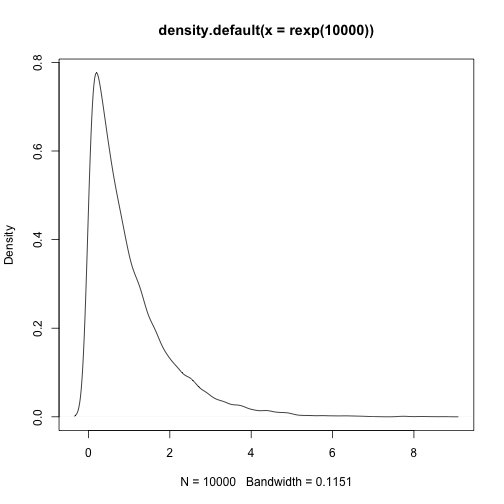
skewness(rexp(10000))## [1] 1.996753kurtosis(rexp(10000))## [1] 5.660961diamonds %>% summarise(kurtosis=kurtosis(carat), skewness=skewness(carat))## # A tibble: 1 × 2## kurtosis skewness## <dbl> <dbl>## 1 1.26 1.12Summary
Get to know your data. Is it continuous or not?
If it's not continuous, then it's counts. Plot the counts with a bar chart. Know what the mode is (the most frequent category), know, generally, the frequency of your variables.
If it's continuous, calculate the min, the max, the mean, the median. Is it flat, is it spiked, is it skewed, is it very spread out?
Are there many missing values?